全2374文字
サイバー攻撃の多くはソフトウエアの脆弱性(セキュリティー上の欠陥)を悪用する。このため修正プログラム(パッチ)の適用といった対策が不可欠だがその負荷は高い。
脆弱性は次から次へと見つかるうえに、パッチの適用前には検証が必要だからだ。一方で、全ての脆弱性が攻撃に悪用されるわけではない。もし悪用される可能性を脆弱性ごとに予測できれば、パッチ適用の優先順位をつけやすくなり、管理者の負荷は大きく軽減される。
そこで米メリーランド大学カレッジパーク校と米アリゾナ州立大学の研究者らは、脆弱性が悪用される可能性を機械学習で予測する方法を開発。2022年8月中旬に米国で開催された国際会議で発表した。
一体、どういった方法なのだろうか。
従来の指標では予測が困難
脆弱性の深刻度(重要度)を評価する指標は複数ある。共通脆弱性評価システム(CVSS:Common Vulnerability Scoring System)や米Microsoft(マイクロソフト)の悪用可能性指標(Exploitability Index)、米IBM傘下のRed Hat(レッドハット)によるRed Hat Severityなどが代表的だ。
ただ研究者らによれば、これらの指標で正確に予測するのは困難だという。それぞれの指標にしきい値となる深刻度を設けて、その深刻度以上の脆弱性は「悪用される」と予測したとする。するとその場合の精度(「悪用される」と予測した脆弱性のうち、実際に悪用された脆弱性の割合)は、しきい値をいくつにしても5割以上にならない。
原因の1つは、これらの指標が静的であるためだという。研究者らによれば、脆弱性に対する攻撃のしやすさは刻一刻と変化する。例えば、ある脆弱性に関する詳細な攻撃手法が公表されれば、その脆弱性の悪用可能性は当然高まる。
そこで今回提案された方法では、インターネットで公開されている脆弱性に関する情報を収集し、その時点での悪用可能性をリアルタイムで算出する。論文では、この悪用可能性をExpected Exploitability(EE)と呼んでいる。
ネットで公開されている情報を収集
収集する情報としては、ベンダーやセキュリティー組織が公開する脆弱性情報やSNS(交流サイト)への書き込み、セキュリティー研究者が公開する実証コード(PoC:Proof of Concept)などが挙げられる。
実証コードとは、ソフトウエアに特定の脆弱性があるかどうかを調べるためのプログラム。きちんとしたプログラムではなく、プログラムの一部であることも多い。今回の方法で一番重視している情報は、この実証コードである。
攻撃者の多くは、実証コードを参考にして攻撃プログラムを作る。このため「攻撃プログラムに転用しやすい実証コード」が公開されている脆弱性ほど悪用可能性が高いといえる。
ここでポイントなのが「攻撃プログラムに転用しやすい」という点。一口に実証コードと言っても、内容は様々だからだ。それだけでは動作しないようなプログラム部品やコメント(説明書き)がほとんどの実証コードがある一方で、そのまま攻撃に使えそうな実証コードもある。
過去の研究では、公開されている実証コードの数などで悪用可能性を算出する方法が提案されているが、攻撃プログラムに転用できない実証コードがノイズとなり、かえって精度が落ちるという。このため今回の研究では、実証コードの「中身」を吟味する。
具体的には実証コードに含まれるプログラムコードとテキストを分離して、それぞれの内容や複雑性などを評価する。例えばプログラムコードが複雑であればあるほど、攻撃プログラムに転用される可能性が高いと考える。
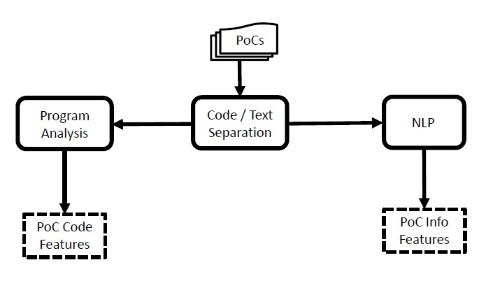
実証コードの評価方法
(出所:論文「Expected Exploitability: Predicting the Development of Functional Vulnerability Exploits」講演資料)
[画像のクリックで拡大表示]
from "鍵" - Google ニュース https://ift.tt/R7HCX3Y
via IFTTT
Bagikan Berita Ini














0 Response to "サイバー攻撃が狙う「脆弱性」を機械学習で予測、鍵はネットに転がる実証コード - ITpro"
Post a Comment